

What is Counterintelligence?
Counterintelligence typically describes an activity aimed at protecting an agency’s intelligence program from an opposition’s intelligence service.
More specifically Information collection activities related to preventing espionage, sabotage, assassinations or other intelligence activities conducted by, for, or on behalf of foreign powers, organizations or persons.
In terms of this blog post, we’ll use a Honeypot based approach to see who is using looking at the Robots.txt file and scanning folders we’ve asked them not to and record information about the HTTP call for later review and analysis.
What is the Robots.txt File?
The Robots.txt is just a simple text file meant to be consumed by search engines and web crawlers containing structured text that explains rules for crawling your website.
In theory, the Search Engines are supposed to honor the Robot.txt rules and not scan any URLs in the Robots.txt file if told not to.
Robots.txt was supposed to help avoid overloading websites with requests. According to Google, it is not a mechanism for keeping a webpage out of Google Search results.
If you really want to keep a web page out of Google you should try adding a noindex tag reference or password-protect the page.
With a Robots.txt file, you can create rules for user agents specifying what directories they can access or disallow them all. It all sounds OK in principal but on the internet, nobody really plays by the rules.
In fact, the Robots.txt file is one of the first places a bad guy might look for information on how your website is structured.
Too many websites make the mistake of using the Robot.txt file without giving thought to the fact they might be rewarding possible OSINT or hacking reconnaissance efforts at the same time.
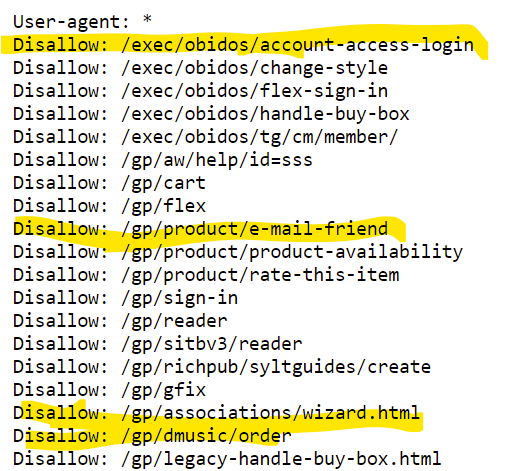
A Look at Amazon.com’s Robots.txt File
If we take a quick look a big website like Amamzon.com to see what their Robots.txt file looks like all we have to do is load up this URL.
https://www.amazon.com/robots.txt
What files or directories does Amazon tell the Google search engine not to crawl or index?
It looks like account access login and email a friend features are off limits so these are the first places a hacker will be looking.
More Sample Robots.txt files from Google
# Example 1: Block only Googlebot
User-agent: Googlebot
Disallow: /
# Example 2: Block Googlebot and Adsbot
User-agent: Googlebot
User-agent: AdsBot-Google
Disallow: /
# Example 3: Block all but AdsBot crawlers
User-agent: *,
Disallow: /You can find more detailed information on how to make more complex robots.txt files over on the Google Search Central area for developers.
A Real World Robots.txt Based HoneyPot Example
Using the Robots.txt file as part of a honeypot system, we will broadcast a list of honeypot folders we don’t want search engines to index, but in this case, it will be a list of folders pointing to honeypot pages.
Having a honeypot / data collection service running in these folders allows you to see who is using the Robots.txt file to scan your web server thus tipping you off that OSINT footprinting activity on your webserver or domain names may be taking place.
These folders have a Disallow rule but contain honeypot code to collect information about the HTTP calls made against them and in some cases to redirect the user-agent somewhere else.
A Sample Honeypot Robots.txt File
A Sample Robots.txt file where we are telling all user-agents to stay away from our admin, wordpress and api folders.
# All other directories on the site are allowed by default
User-agent: *
Disallow: /admin/
Disallow: /wordpress/
Disallow: /api/
The Robots.txt file I’m discussing in this post was collected from the online classifieds website, FinditClassifieds.com.
If you try to hit any of the URLs found in the Robots.txt file, you’ll be redirected to a Rick Roll video on YouTube.com. IP address data is collected in a log for a more detailed review.
Each one of these honeypot URLs do a little something different.
The first honeypot URL replies with something naughty, the second logs it as a scan and the third URL is the Rick Roll redirect.
- https://www.FinditClassifieds.com/api/
- https://www.FinditClassifieds.com/admin/
- https://www.FinditClassifieds.com/wordpress/
Depending on the honeypot page, you can collect data from the user-agent and log it before you redirect them off to the Land of Oz.
Using a tool that was originally created to be helpful that ended up becoming dangerous can now be a double agent if you set it up correctly.
Hoping this helps someone on their InfoSec journey.
~Cyber Abyss